Touching The Limits Of
Knowledge
Cosmology and our View of the
World
Is Information an Irreducible Entity in the World?
Lead: Austin Purves
4/29/2008
Summary by Alex Miklos
Information: Definitions, Understanding, and Implications
At this point in the semester we have covered topics ranging from what constitutes
life to what constitutes consciousness to what constitutes the “dark”
96% of the universe, yet underlying each and every discussion and each and every
presentation is an entity so fundamental, so basic, that it is easily neglected.
It is an entity ignored so often in common discourse either because it is taken
for granted or because the concept itself rests on the most massive of scales.
Austin Purves accepted the challenge of creating a presentation to help identify,
examine, and explain the most essential and omnipresent unit of the universe,
the entity of information.
How does one begin to define information? Three approaches are utilized in
order to grasp a basic idea of what to look for in defining it. The three approaches
are:
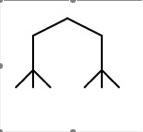
| Reductionist |
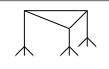
Non-Reductionist |
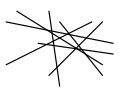
Antireductionist |
|
This approach believes that information can be reduced into
a single concept from which all else is derived.
The problem with reductionism is that it tends to place
restrictions on what can or can not be defined as information since there
is only one central concept. This is problematic when considering the
severe differences between distinct entities in the universe (e.g. tree
rings and poetry).
|
This approach leans towards the idea that information consists of multiple
central notions rather than just one.
A non-reductionist approach is the plausible when dealing with the task
of defining information in acceptably flexible terms.
|
This approach holds that there is no central binding concept of information
and that information has many different natures and can neither be reduced
nor connected in any way.
Just as with the reductionist problem of restricting the definition of
information, antireductionism also limits our understanding of information
since it basically states that the search for a definition of information
is ultimately futile. |
|
|
|
|
Floridi, author the article “Information,” favors a non-reductionist
approach in order to define what information actually is. His goal is to define
one specific concept, namely semantic information, in hopes
that it will turn out to be one of the central concepts characteristic of the
diagram depicting non-reductionism. The term semantic can be
understood to mean that which pertains to language or words and therefore must
be attributed to a conscious observer, for what are words without an intelligent
interpretation of some sort? But before delving into the definition of semantic
information, Austin offers us the Cambridge Dictionary of Philosophy definition
of information. It defines information as an objective entity that can be carried
by or generated by messages or cognizers but exists without any such media.
This ambiguous definition leaves much to the imagination and helps very little
in actually defining anything, as Professor DeVries pointed out. Floridi tries
to clarify this definition by suggesting two forms of information via Edgar
Alan Poe’s The Raven and Ray Bradbury’s Fahrenheit
451. Decidedly, there are differences between the information associated
with The Raven and information associated with tree rings or claps
of thunder, all of which points back to the plausibility of non-reductionism
as a means of understanding information. [Side note: The reductionist approach
is currently in effect for physicists who are researching ways in which to formulate
a coherent theory of unification of all the forces of the universe.]
Floridi proposes a general definition of information (GDI):
- S is an instance of information, understood in
terms of semantic content if and only if:
- s consists of n data (d), for n ≥ 1
- The data are well-formed (i.e. words, not scribbles although scribbles
can be considered data of the previous type)
- The well-formed data are meaningful
Strictly concerning a datum (singular data), it can be understood as a lack
of uniformity of symbols, therefore defining scribbles into the realm of information.
Next, several types of neutrality should be examined in order to conceive of
a better formulation of what the GDI accepts as information. Neutrality here
should be taken to mean the vastly encompassing nature of the GDI as a definition
of information. The following types of neutrality show just how broad the GDI
is.
Typological Neutrality sets out to divide data into four separate
types:
- Primary data: A simple sequence of ones and zeros without any uniformity
or coherence other than the fact that there is something.
- Metadata: “About” data, meaning the format or language through
which one can understand a sequence of primary data. Unicode is an example
of metadata since it makes strings of binary digits intelligible as alphabetic
letters.
- Operational data: Can be understood as the usage and storage of data, e.g.
an operating system or types of RAM.
- Derivative data: Data extracted from any of the, or combination of the,
first three types of data.
To make heads and tails of this notion, Professor Davis offers a biological
illustration of the four data types. He purports that primary data
can be seen as the strand of DNA itself. The fact the nitrogen bases of the
DNA nucleotide are A, C, T, G can be considered the metadata since
it makes something out of the constituents of the DNA strand. The operational
data can be seen as the genetic code, that is, the encoding of different
codons and anticondons to amass a string of amino acids. It is the utilization
of the DNA strand and the way it is organized to synthesize proteins. Finally,
the derivative data is the actual synthesis of proteins from long strands
of amino acids. It is the meaning behind a thread of nitrogen bases. What this
all shows in terms of the GDI is that a general definition of information does
not prefer a particular type of data since all of the universe necessarily consists
of data of the four types. [Side note: All single letters of the alphabet are
data, but to be considered well-formed there must be associated with it an element
of operational data, i.e. the letter I is a datum and in some
uses is itself well-formed since some meaning is built into the letter, information
specific to a concept in the English language.]
Taxonomic Neutrality is the next type of data distinction.
The term taxonomic refers to classification. It shows that a datum can be reduced
to a lack of uniformity between two variables [depicted as d = (x ∫ y)].
This means that datum is expressed in terms of a relationship between two things.
For example, a black dot on a white page is devoid of meaning aside from the
fact that it contrasts with the white of the paper. What this means in terms
of the GDI is that a general definition of information is neutral to the class
of relations used to specify a certain datum.
Ontological Neutrality sets out to separate the possibility
of the existence of information without first the existence of some sort or
type of data. Ontological refers to the essence or nature of being. This does
not imply that information must necessarily be something of a material nature,
nor does it even imply that the data in question must be of a material nature.
It simply states that the existence of information owes itself to the fact that
prior to its own existence there necessarily must have existed some sort or
type of data, be it non-extended or be it material. This again shows the GDI
to be a definition that seeks to include as much as possible into the definition
of information. [Side note: Other interpretations of the essence of information
may hold that data can exist in thought or consciousness, with no need for matter
at all, a la Berkeley.]
Genetic Neutrality is the property of the general definition
of information that data can have semantic meaning independent of an informee.
For example, the Egyptian hieroglyphs would therefore have semantic meaning,
to a non-Ancient Egyptian, before they were discovered in modern times. This
begs the question: How can there be something with semantic meaning if there
is not one who can ever interpret it as more than primary data? (Remember, primary
data does not necessarily have semantic meaning.) GDI would say that information
without an interpreter still has semantic content no matter who can or can not
interpret it, since GDI is a flexible standard for defining information. Another
brain teaser involving genetic neutrality is: If a tree falls
in the woods and no one will ever hear it, is there really data and meaning
in the sound waves produced? The answer, of course, is yes there is information
in any and all sound waves, but this may be a little bit off the track of an
appropriate context for semantic information. Professor DeVries clarifies this
notion by adding that a personless universe which still consists of causal interactions
still has information, although not semantic. Professor Davis then adds that
genetic information (DNA nitrogen bases and genetic the genetic code) seems
to be semantic, since A’s T’s C’s and G’s are alphabetic
pictorials and can even be made into GATTACA can provoke thoughts of Uma Thurman
and Ethan Hawke. Professor DeVries ties it together by recognizing that the
genetic code is prospective, or forward looking since proteins will
be synthesized which shows that it is analogous to semantic meaning in that
semantic information is necessarily prone to misuse just as protein are sometimes
made incorrectly.
To recap the GDI:
- It is an attempt at a sufficiently flexible definition of semantic information
- Information can exist without an informed observer
- But it is not obvious that this type of information in likely to exist without
an intelligent producer
Shannon’s Theory is an attempt to quantify an amount of information.
He uses the equation
I = log2 (1/p)
where p is the probability of a certain state being chosen at random
and I is the amount of information constituted by that state. This
means that a highly unlikely state, i.e. lower case p, will constitute
a large amount of information, I. The amount of information that can
be represented by a system with only one state (p = 1) is zero. The
amount of information that can be stored by a single letter in the English alphabet
is ideally (p = 1/26) about 4.7.
Shannon’s equation bears a striking resemblance to thermodynamic entropy.
The second law of thermodynamics states that the entropy of a closed system
is irreducible and can only increase. Just as this is practical in physics,
are there practical consequences for information too? Could some similar law
be discovered in the case of info? Could it be irreducible?
It is important now to touch on ways of destroying information since that will
lead to answers to questions dealing with its reducibility. Would destroying
the medium or physical implementation of the information destroy it? No, because
if you smash a floppy disk the encoded information is still written on the tiny
pieces of plastic, even though it is unreadable now. But what if you threw your
floppy disk into a black hole? Would recovery be impossible?
Hawking radiation says that yes, information lost in a black hole can eventually
be recovered! Hawking radiation is the slow dissipation of the contents and
structure of a black hole. However, it is still unclear how information is stored
in a black hole.
Some final questions left for us to ponder:
Can we find a unified theory of information based on a single concept?
Could there be an irreducible or conservation law regarding information?